Model Context Protocol (or MCP) has been the new hotness lately. It's a standardized interface for integrating your code, resources, and other data with LLMs.
Here's generally how the architecture works. Sry for legit note paper, I'm a boomer.
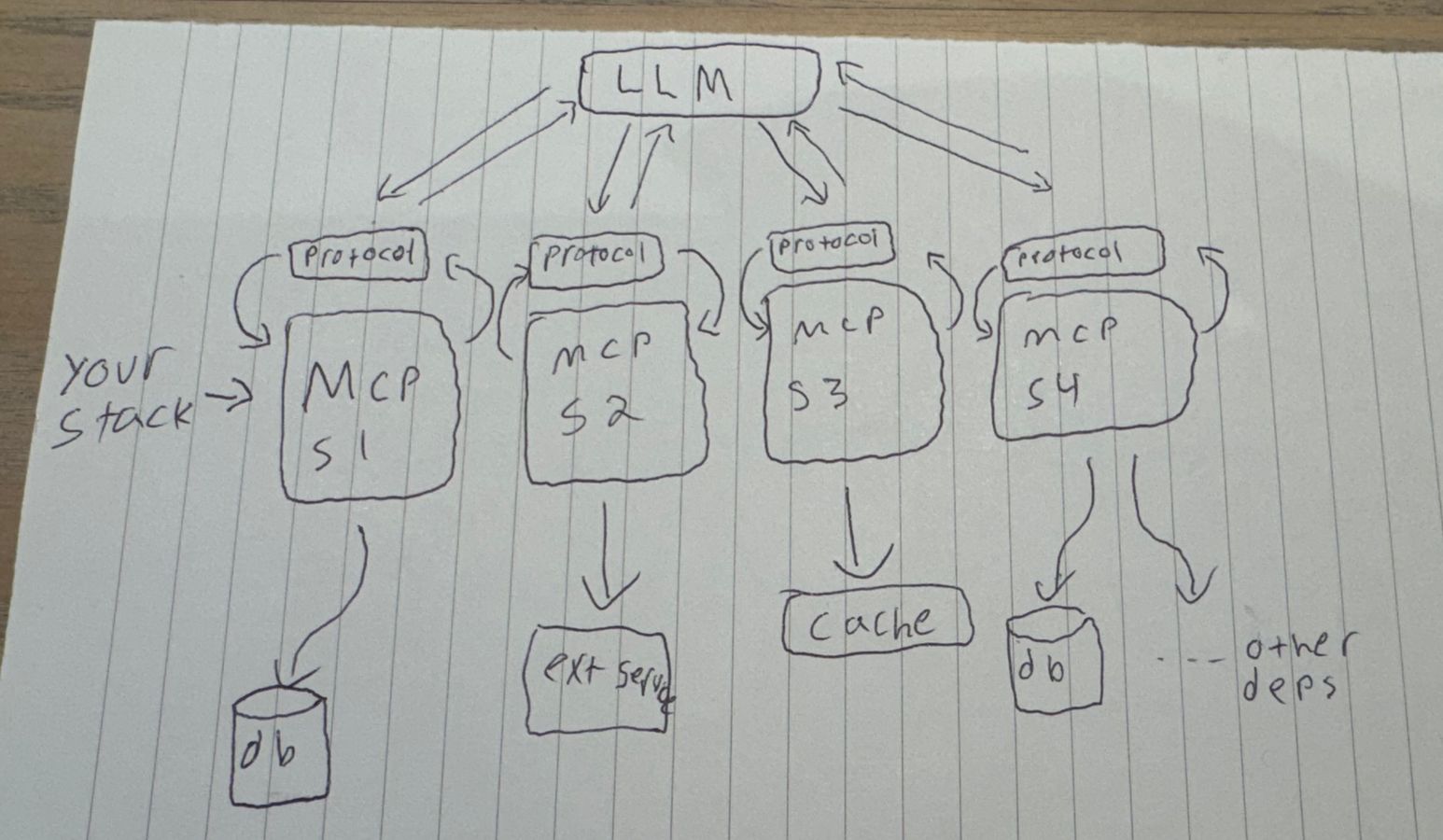
Anyways, here are some pro tips when integrating MCP.
Descriptive Metadata
Pretty obvious for MCP related stuff, but yeah. Try to describe exactly what each tool does. Write detailed use cases for when to use each tool and try to make these use cases very distinctive so that the LLM can decide when to use it.
Consider including specific parameters or attributes of the requests you want to handle with each tool. You can approach this similar to writing documentation for an API, except humans won't read it so you can skip the BS pleasantries.
Agentic Single Responsibility Architecture
Don't make your functions do too many things. It will likely confound the LLM.
Remember, LLMs are not reasoning about things according to their own volition. You can convince them from atheism to new age spirituality and back within the course of 10 minutes.
These functions need to handle a single responsibility and do that thing very well. If you find the model over indexing on a specific action, making the function more complex usually does not mitigate this.
Schema Validation With Good Visibility
LLMs are inheritly unpredictable and stochastic. Consequently, you must build your system defensively.
Of course this will include thorough validation, but it's also great to have comprehensive visibility and interpretability. Monitor what passed or failed, as well as the breakpoints of where they occurred.
Routing and Cancellation
You should also keep a keen eye out for interaction or routing issues. Maybe nothing explicitly fails, but if you have many tools across your stack of agents, things can get cumbersome fast.
Monitor behavior frequently and see if the routing works as you expect. Try to keep the stack lean so you can pivot and iterate as needed.
If something does fail, try to optimize the speed-to-failure. It's better to bail out of the function early for higher likelihood of recovery on the task using other tools or the model itself.
Plus, you won't contribute to climate change as much by running those GPUs superfluously.
Stream On, Stream On
In a GPU's memory pages, live and learn from tools and from sages...
Should have been a rockstar, lol.
If you're building a highly interactive agent, it's a based approach to make extensive use of streaming. For long running tasks, you can send progress updates as the task progresses using the server exchange specification.
But, server exchange isn't just for progress updates. Agentic workflows can implement sending other types of data as well. If you have a task that generates results procedurally and these intermediate results are useful, perhaps stream them as they become available.